Карта освещения для 2D спрайтов и изображений
25 мая 2020 г.
Чтобы в 3D окружении текстуры выглядели более выпукло, они реагируют на освещение используя Normal map. Это такая дополнительная карта-текстура, пиксели которой сообщают об вымышленном угле наклона отражения света от текстуры. Такой приём используют не только в 3D но и в 2D играх на спрайтах.

Чтобы упростить создание таких карт даже есть несколько инструментов, например, Laigter, Sprite Lamp, Sprite DLight. Вот, например, наглядное видео про генератор Sprite Dlight, который автоматически по спрайту создаёт такую карту, поскольку информации в спрайте обычно достаточно: придается общая выпуклость всему спрайту по контуру непрозрачности, и, дополнительно, выявляется и накладывается объём у деталей, исходя из контрастной информации соседних пикселей.

И вот недавно появилась публикация о продвинутом инструменте для изменения освещения на основе любой 2D информации. На основе имеющегося рисунка составляется представление об освещении, и, затем, появляется возможность отделить цвет от освещения и поменять источник освещения на изображении.

Это означает, что через какое-то время следует ждать инструмент и для исправления и для автоматического рисования освещения. Разумеется, эти инструменты не заменят рисование света и теней руками, но серьёзно сократят время потраченное на рутинную работу по поиску подходящего освещения и созданию наброска, что облегчит значительную часть работы.
Вот инструкция как имеющуюся карту нормалей можно использовать в 2D графике.

Как вам это?
![]()
Из каких фотографий создавалась графика для Doom
28 марта 2020 г.
Для того чтобы сделать реалистичную графику для игр Doom и Doom 2: Hell on Earth разработчики использовали фотографии. Что же они фотографировали? Вот видеоролик, в котором показаны конкретные предметы, страницы книг и клипарт, всё что использовалось в iD Software как основа для текстур и спрайтов в этих шутерах.

Более подробно о том как были сделаны спрайты для монстров.

Как вам это?
![]()
Как превратить картинку в изображение для ZX Spectrum
25 сентября 2019 г.
Недостаток информации в художественном изображении и его мозаичность добавляют изображению притягательности, поскольку включают воображение, чтобы достроить объекты, решить задачу их поиска. Восьмибитная графика кроме того имеет ещё и шарм ностальгии. На компьютерах ZX Spectrum графика была «девятибитная», в каждой клетке 8×8 пикселей могло быть только два цвета из общих 8 и их двух видах яркости. Заинтересовался как эти ограничения удобно воспроизводить сегодня и нашёл две интересных программы, которые позволяют за полчаса сделать честный zx-art.

Вот они:
Image Spectrumizer
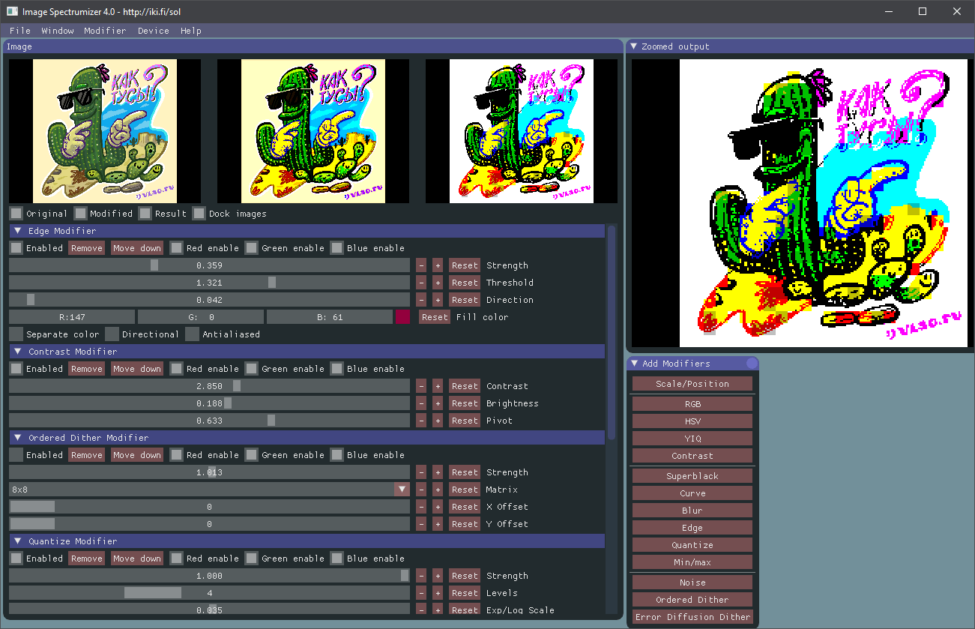
Умеет превращать любое изображение в «спектрумовское» с ручными подстройками. Для вывода есть различные фильтры, помогающие интерпретировать изображение: уровни, тип диртеринга, эффекты на границах контраста. За несколько минут подбора и небольшой ручной чистки от шума можно получить отличный аутентичный результат.
ZX Paintbrush
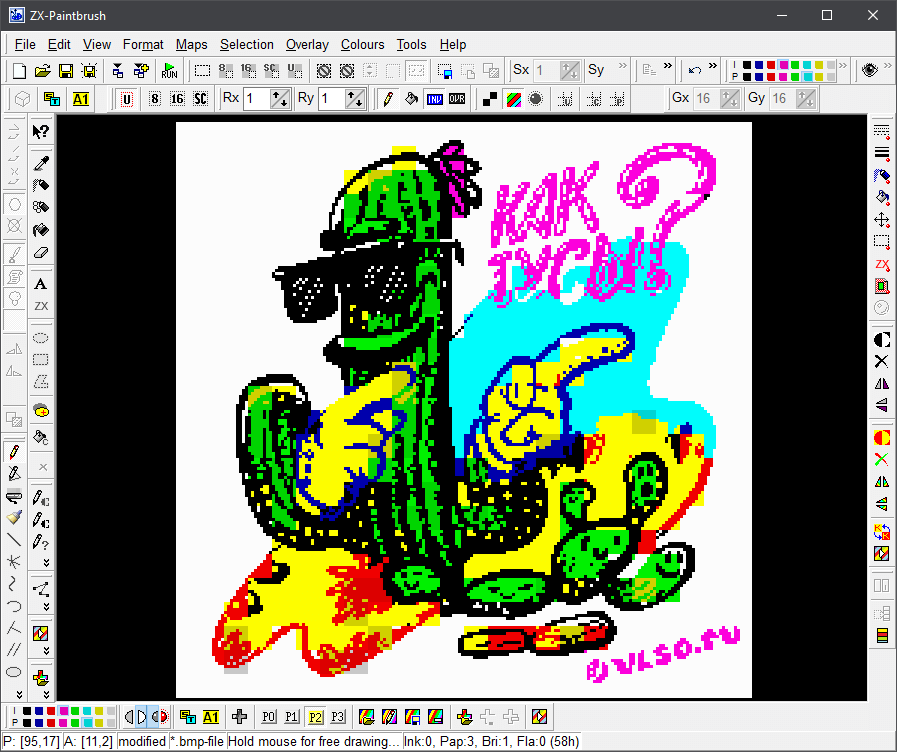
Полноценная программа для рисования на PC в условиях спектрумского холста. Много видов кистей, диртиринг, работа с палитрами. Импорт и экспорт множества форматов. Достаточно всего, чтобы делать зет-икс-арт.
Да, про ограничения в графике на ZX Spectrum я писал однажды.
Как вам это?
![]()
21 февраля 2017 г.
Скульптуры, которые при вращении и съемке на камеру становятся анимированными из-за стробо-эффекта.
Как вам это?
![]()
Kingdom of Colors
16 января 2017 г.
Thomas Blanchard снимает в высоком разрешении плохо смешиваемые цветные жидкости. Очень красиво выглядит.
Прокомментировать в Телеграме