Создание tileset спрайта из тайлов для карты в 2D игре
17 апреля 2023 г.
Сколько надо кусочков платформы нарисовать для аркадной 2D игры? Какие комбинации и сочетания плиток бывают и как можно упростить их создание? Заинтересовался этими вопросами и обнаружил за ними науку.  Оказывается, за созданием тайлов для игр стоит непростая геометрия, в зависимости от того какие сочетания с соседними клетками по горизонтали, вертикали и диагоналям мы хотим предусмотреть. Вот потрясающий сайт на английском популярно рассказывающий про все виды тайлинга, навигация по главам справа в колонке: http://www.cr31.co.uk/stagecast/wang/intro.html
Оказывается, за созданием тайлов для игр стоит непростая геометрия, в зависимости от того какие сочетания с соседними клетками по горизонтали, вертикали и диагоналям мы хотим предусмотреть. Вот потрясающий сайт на английском популярно рассказывающий про все виды тайлинга, навигация по главам справа в колонке: http://www.cr31.co.uk/stagecast/wang/intro.html
Кратко. Математик Ван Хао описал законы для плитки на плоскости по разным правилам, связал с машиной Тюринга и всё систематизировал. Вот заумная статья про систематизацию тайлов: https://www.boristhebrave.com/2021/11/14/classification-of-tilesets/ Квадратные тайлы можно придумывать по разным правилам. Основные это — учитывать только соединение сторон (4), или соединение углов (4), или и сторон и углов (8). В современном мире это знание применяют дизайнеры текстур — тайлингом решается всё, от обоев с цветочками до кельтских узоров. И применяют создатели 2D игр, чтобы уметь рисовать по клеточкам землю в море или землю висящую в воздухе, в зависимости от того какую двухмерную игру они делают.
В качестве простого примера, вот варианты спрайтов из 16 видов плитки со всеми вариантами двуцветных углов. Тайлы собраны в спрайт как один остров, что удобно при разработке, чтобы видеть, как изображения состыкуются.

Самая важное знание: что для того, чтобы учитывать и углы и стороны, потребуется придумать 47 видов тайлов. 47 плиточек можно расположить в один спрайт в квадрат 7×7=49 (2 лишних) или в 8×6=48 (1 лишняя) или в 12×4=48 (1 лишняя). Вот примеры как 47 плиток собрать в один спрайт, чтобы было удобно наблюдать соединения:
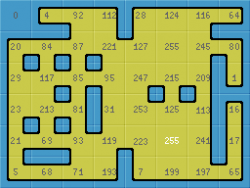
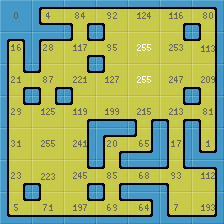
Кроме того, сформировался опыт, как имея 5 тайлов разрезать каждый на 4 кусочка и собрать их в 47 комбинаций. То есть из такой картинки:
![]()
Автоматически сгенерировать вот такой стандартный шаблон 12×4:

Такую текстуру стало принято использовать в 2D игровых движках, поскольку она наглядна, как палитра, например, для создания уровней в играх-платформерах или для создания лабиринтов в RPG с видом сверху вниз.
Как вам это?
![]()
Black Ink растровый редактор с блочным автоматом
2 декабря 2020 г.
Обнаружил на распродаже в Steam очень любопытную рисовалку Black Ink. Графическая программа с акцентом на собственную цифровую природу. Действия производятся над растровыми слоями, но слои можно пропускать через неразрушающие фильтры, применять стили, и даже писать шейдеры. При этом все инструменты можно выстроить в блочном автомате, это такой инструмент из блоков и линий соединяющих элементов в результат, который хорошо известен и цифровым музыкантам и трехмерщикам и визуальным программистам. И вот теперь есть серьезная программа с блочным автоматом. Да, это не новинка, есть множество графических генераторов с автоматами, большинство для генерации текстур. Но вот соединение с обычным рисованием руками настраиваемыми кисточками это самый серьезный из известных мне. Это фотошоп в мире генераторов.

Кстати, Фотошоп до версии CS5 поддерживал удивительный по силе плагин-инструмент Pixel Bender, но к CS6 всю поддержку плагинов манипулирования графикой отпилили, видимо из политических соображений, чтобы не дать расти рынку плагинов Фотошопа отдельно от только создавшегося Creative Cloud.

Black Ink работает на GPU под Direct X, имеет очень плавный интерфейс, не встретил ни одного мимолётного фриза пока тестировал. Буду осваивать, на официальном канале есть набор уроков, вот он.
Как вам это?
![]()
Карта освещения для 2D спрайтов и изображений
25 мая 2020 г.
Чтобы в 3D окружении текстуры выглядели более выпукло, они реагируют на освещение используя Normal map. Это такая дополнительная карта-текстура, пиксели которой сообщают об вымышленном угле наклона отражения света от текстуры. Такой приём используют не только в 3D но и в 2D играх на спрайтах.

Чтобы упростить создание таких карт даже есть несколько инструментов, например, Laigter, Sprite Lamp, Sprite DLight. Вот, например, наглядное видео про генератор Sprite Dlight, который автоматически по спрайту создаёт такую карту, поскольку информации в спрайте обычно достаточно: придается общая выпуклость всему спрайту по контуру непрозрачности, и, дополнительно, выявляется и накладывается объём у деталей, исходя из контрастной информации соседних пикселей.

И вот недавно появилась публикация о продвинутом инструменте для изменения освещения на основе любой 2D информации. На основе имеющегося рисунка составляется представление об освещении, и, затем, появляется возможность отделить цвет от освещения и поменять источник освещения на изображении.

Это означает, что через какое-то время следует ждать инструмент и для исправления и для автоматического рисования освещения. Разумеется, эти инструменты не заменят рисование света и теней руками, но серьёзно сократят время потраченное на рутинную работу по поиску подходящего освещения и созданию наброска, что облегчит значительную часть работы.
Вот инструкция как имеющуюся карту нормалей можно использовать в 2D графике.

Как вам это?
![]()
Как распознать голос из видео на Youtube в текст
2 мая 2020 г.
Отличный простой, полуручной, способ сделать титры для собственного видео на ютюбе, не перенабирая текст руками:
Для распознавания записи речи с Ютюб в текст надо установить виртуальную звуковую карту VoiceMeeter, сделать в Windows устройство записи по умолчанию VoiceMeeter Input (виртуальный микрофон), а устройством воспроизведения по умолчанию VoiceMeeter Output (виртуальные колонки). Выбрать в Google Docs меню Инструменты → Голосовой ввод, в появившемся окне с большая иконкой микрофона выбрать в маленькой выпадалочке язык распознавания. Теперь во втором окне запустить видео с речью, и тут же вернуться в окно Google Docs и включить Распознавание (Нажать, на большую иконку микрофона, чтобы стала оранжевой). Фокус с окна Google Docs нельзя убирать! После этого останется лишь отредактировать текст руками, потому что распознавание не идеальное и абзацев автоматически не расставляет.
Разумеется, таким образом можно любой видео или аудиофайл в текст распознать.
Как вам это?
![]()
Будущее за нейро коммерцией!
18 марта 2020 г.
Предсказываю, что первой эффективной областью массового использования нейросетей и, конкретнее, дипфейков будут интернет-магазины. Конкретнее, там где требуется продемонстрировать как товар подходит именно вам, например, на интернет-витринах одежды.
Вот как я думаю это будет работать: сейчас интернет-магазин может составить достаточно ясную картину о вас, спасибо инстаграму и фэйсбуку легко отследить не только интересы но и то как вы выглядете. Заходя на сайт для выбора одежды вам будут показывать не просто заготовленные фотографии товаров на манекенах или непохожих на вас людей. Фотографии моделей в одежде будут на лету изменяться, чтобы выглядеть похожими на вас, вашу расу, комплекцию — всё, что поможет вам проассоциировать товар с вами. Такой генератор очень сильно увеличит продажи — то что похожие фотографии продают лучше хорошо известно и вы сами можете это за собой заметить.
Впрочем брать информацию из соцсетей не обязательно. Достаточно будет устроить автоматическое А/Б тестирование, в ходе которого нейросеть будет выдавать гипотезами всё более продающие изображения для каждой выборки посетителей. В итоге нейроэволюционный отбор добудет самые подходящие фотографии под каждую геолокацию.
Ну и чтобы два раза не вставать, посмотрите на любопытный список онлайн генератороров, какие есть в общем доступе: https://thisxdoesnotexist.com/
Вот, например, случайное ненастоящее лицо:

Случайная ненастоящая абстрактная картина:
А вот случайный ненастоящий котик:
Прокомментировать в Телеграме